Expand Machine Learning Analysis to More Data Types
Investigating biological systems often requires the use of multiple technologies and assay types to understand states and processes throughout different components of organisms and their cells. Measuring system-wide immune responses requires significant breadth and depth of data 1, 2, 3.
For assay types that produce data in formats similar to cytometry, a numerical matrix with the relative quantity of a biological marker being measured (proteins, RNA, DNA, physiological parameters, demographic data) for different observations (cells, samples, patients), machine learning (ML)-assisted analysis can be applied to these datasets to help investigators uncover unique relationships. You can run machine learning-based dimensionality reduction and clustering tools available in the Cytobank platform across additional data types. Discover biomarkers and explore cellular interactions and other experimental outcomes faster and more comprehensively leveraging the scalable compute and collaborative power of the cloud.
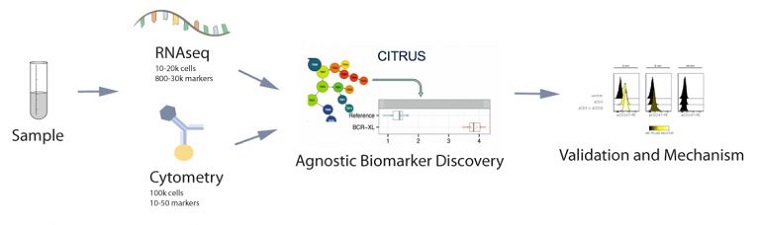
Figure 1. Analyze Multiple Single Cell Data Types to Discover More. Leverage the discovery potential of broader, non-cytometry data types such as genomics and transcriptomics. Then cross-validate and delve deeper into mechanism with proteomics.
Which Data Analysis Methods to Use?
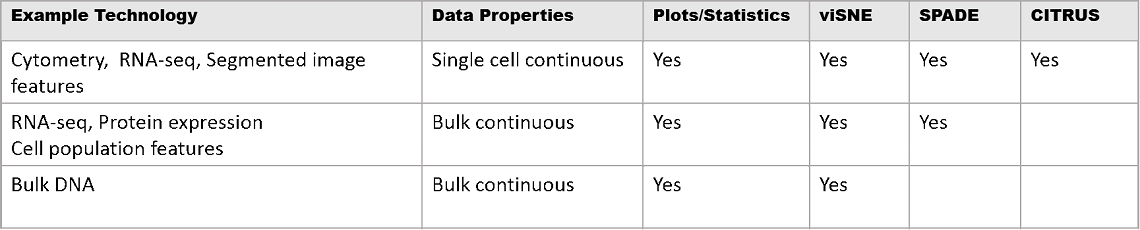
The analytical strategies taken on any data will depend on the nature of the data. See below which analytical methods you can apply on the Cytobank platform based on the example technology and data properties.
Analyzing more data types on the Cytobank platforms allows you to capitalize on more of the data you’re measuring in your studies. For example, identify populations within single cell data sets and then validate results with other data types. Start with single cell RNAseq data and identify a set of statistically significant population-specific biomarkers, then validate them with cytometry data and dive deeper into mechanistic protein studies. This approach allows you to start broad and agnostically and end up with a reduced set of markers for downstream repetitive use such as might be useful in clinical trials.
Learn more about CITE-seq, or Cellular Indexing of Transcriptomes and Epitopes by Sequencing.
Analyze Bulk Data to Visualize Heterogeneity Between Samples
Analyze bulk data to identify groups of samples based on marker expression differences and visualize whether the groups have any association with other outcomes such as clinical features (e.g. treatment arm or age). Pivoting the data, you can also ask whether there are groups of markers that are similar across samples, for example, to potentially reduce the number of markers you need to measure.
Learn more about DROP (Data to Results Optimization Portal).
References:
- Brodin P, Davis MM. Human immune system variation. Nat Rev Immunol. 2017 Jan;17(1):21–29. PMCID: PMC5328245
- Chattopadhyay PK, Gierahn TM, Roederer M, Love JC. Single-cell technologies for monitoring immune systems. Nat Immunol. 2014 Feb;15(2):128–135. PMCID: PMC4040085
- Blank CU, Haanen JB, Ribas A, Schumacher TN. The “cancer immunogram”. Science. 2016 May;352(6286):658-60. PMID: 27151852
